
Rebase as an Alternative to Merge
While merging is definitely the easiest and most common way to integrate changes, it's not the only one: "Rebase" is an alternative means of integration.
Note
While rebasing definitely has its advantages over an off-the-shelf merge, it's also a matter of taste to a great extent: some teams prefer to use rebase, others prefer merge.
As rebasing is quite a bit more complex than merging, my recommendation is that you skip this chapter unless you and your team are absolutely sure you want to use it. Another option is to return to this chapter after you've had some practice with the basic workflow in Git.
Understanding Merge a Little Better
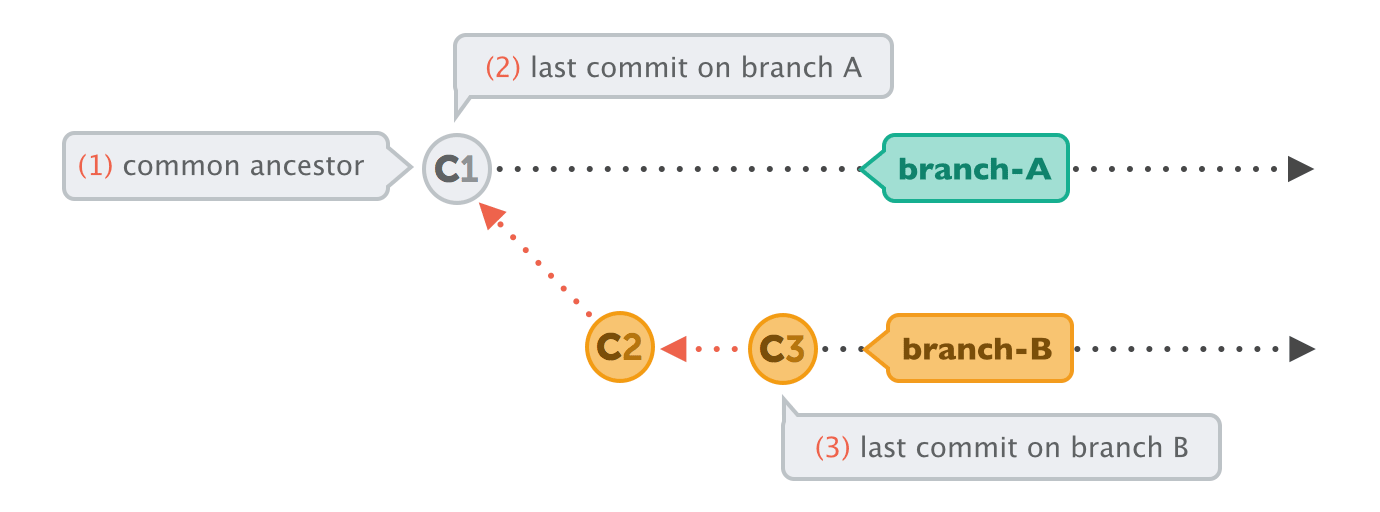
Before we can dive into rebase, we'll have to get into a little more detail about merge. When Git performs a merge, it looks for three commits:
- (1) Common ancestor commit
If you follow the history of two branches in a project, they always have at least one commit in common: at this point in time, both branches had the same content and then evolved differently. - (2) + (3) Endpoints of each branch
The goal of an integration is to combine the current states of two branches. Therefore, their respective latest revisions are of special interest.
Combining these three commits will result in the integration we're aiming for.
Fast-Forward or Merge Commit
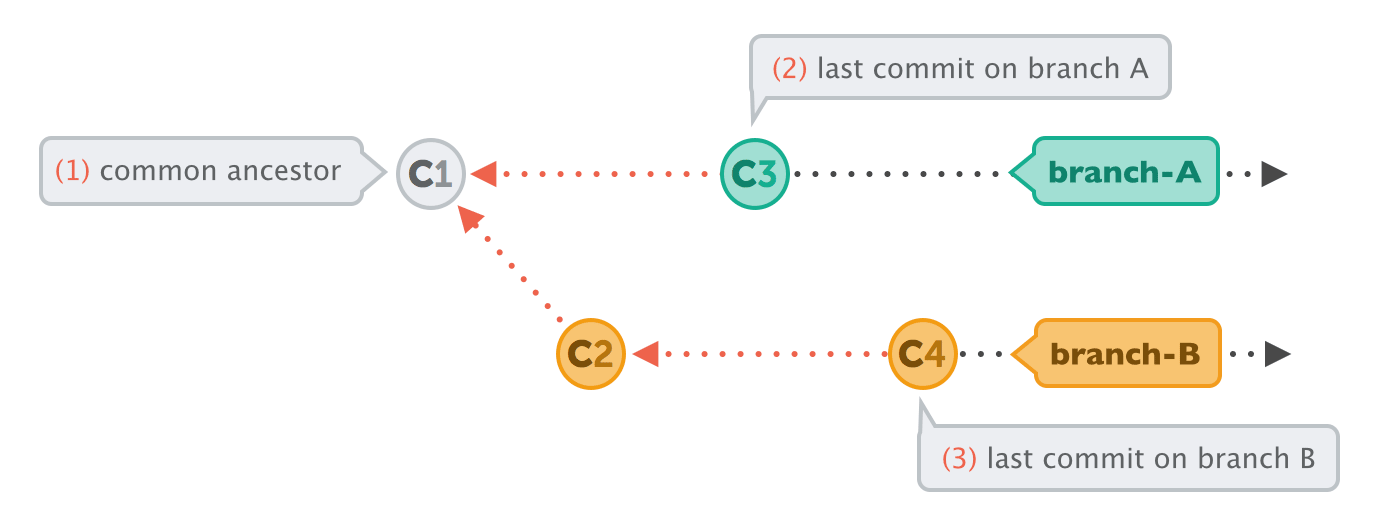
In very simple cases, one of the two branches doesn't have any new commits since the branching happened - its latest commit is still the common ancestor.
In this case, performing the integration is dead simple: Git can just add all the commits of the other branch on top of the common ancestor commit. In Git, this simplest form of integration is called a "fast-forward" merge. Both branches then share the exact same history.

In a lot of cases, however, both branches moved forward individually.
To make an integration, Git will have to create a new commit that contains the differences between them - the merge commit.
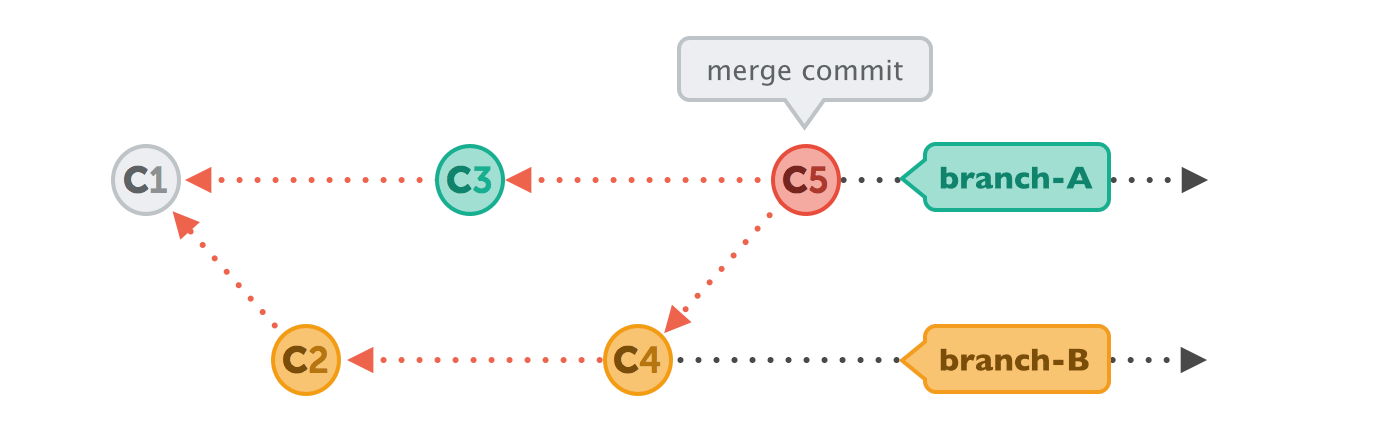
Human Commits & Merge Commits
Normally, a commit is carefully created by a human being. It's a meaningful unit that wraps only related changes and annotates them with a comment.
A merge commit is a bit different: instead of being created by a developer, it gets created automatically by Git. And instead of wrapping a set of related changes, its purpose is to connect two branches, just like a knot. If you want to understand a merge operation later, you need to take a look at the history of both branches and the corresponding commit graph.
Integrating with Rebase
Some people prefer to go without such automatic merge commits. Instead, they want the project's history to look as if it had evolved in a single, straight line. No indication remains that it had been split into multiple branches at some point.
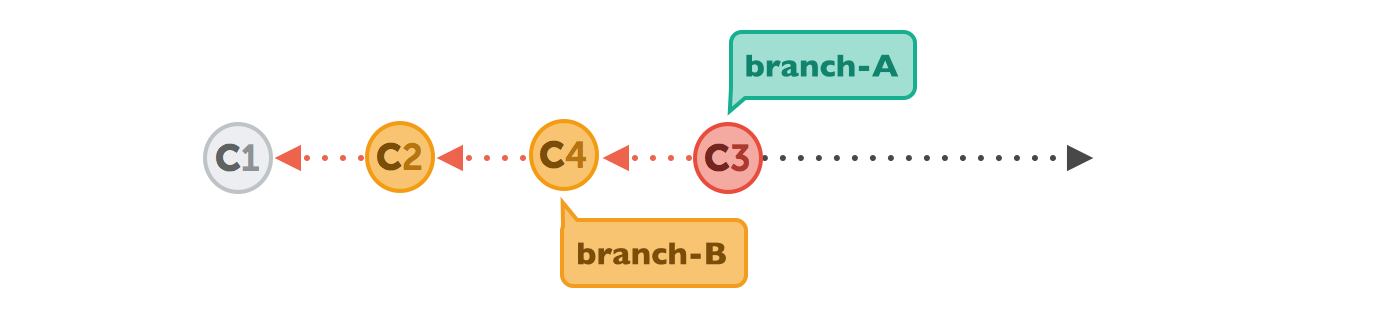
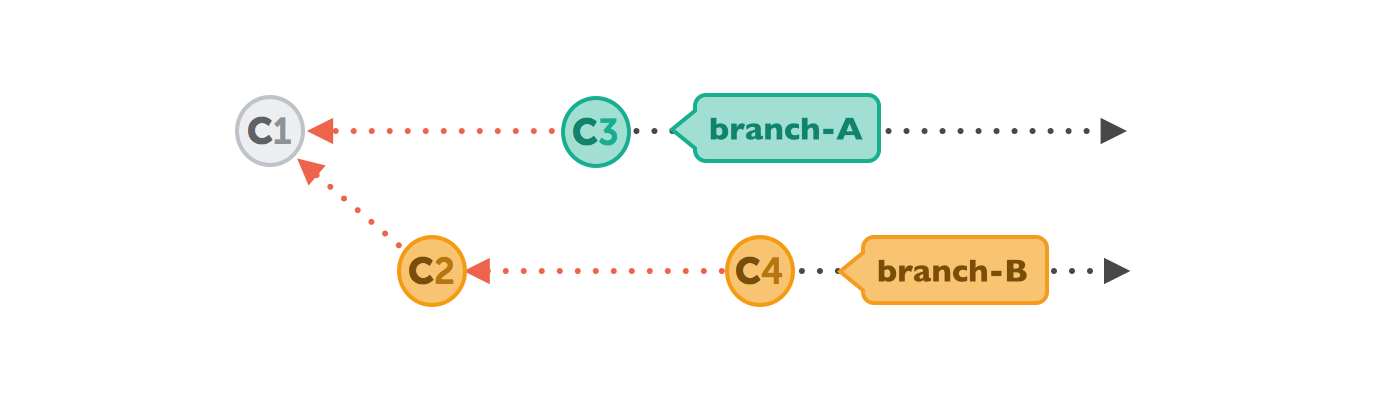
Let's walk through a rebase operation step by step. The scenario is the same as in the previous examples: we want to integrate the changes from branch-B into branch-A, but now by using rebase.
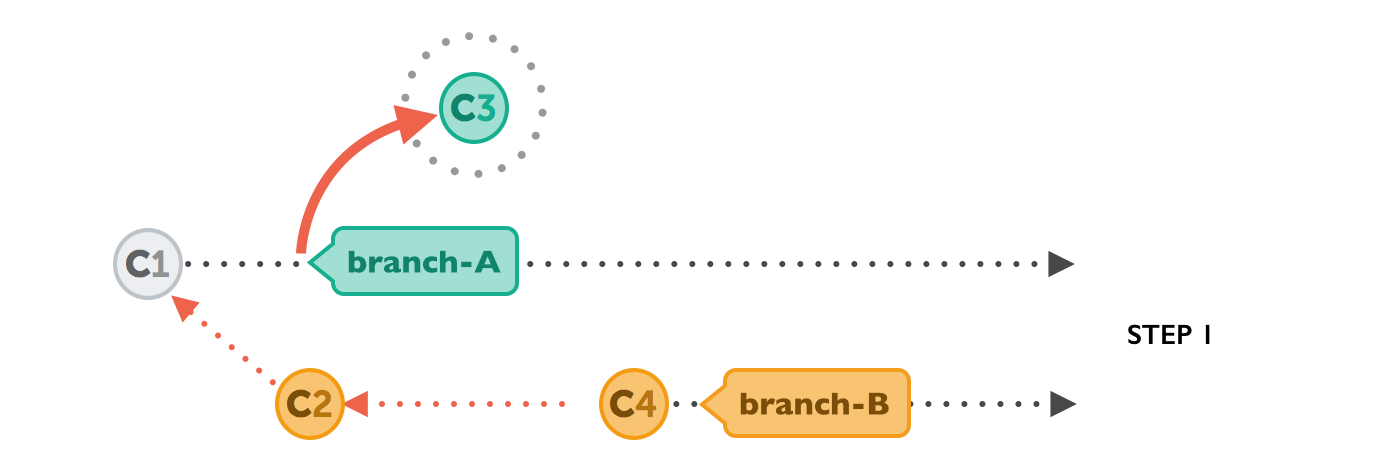
The command for this is very plain:
$ git rebase branch-BFirst, Git will "undo" all commits on branch-A that happened after the lines began to branch out (after the common ancestor commit). However, of course, it won't discard them: instead you can think of those commits as being "saved away temporarily".
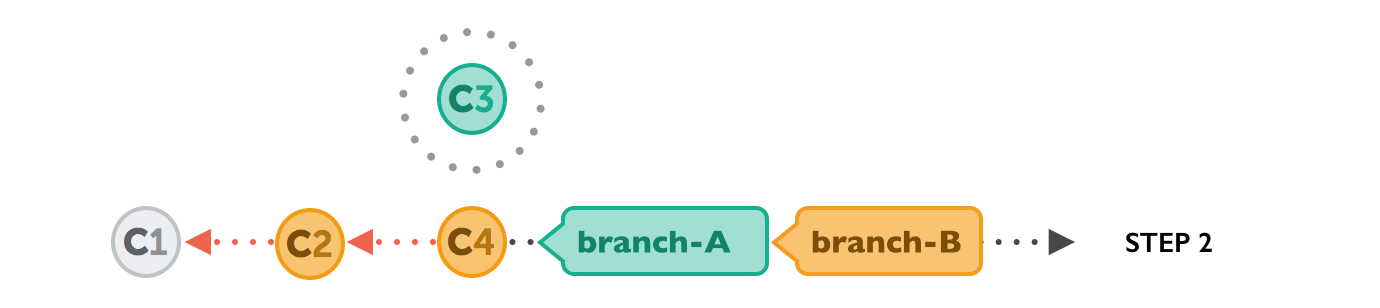
Next, it applies the commits from branch-B that we want to integrate. At this point, both branches look exactly the same.
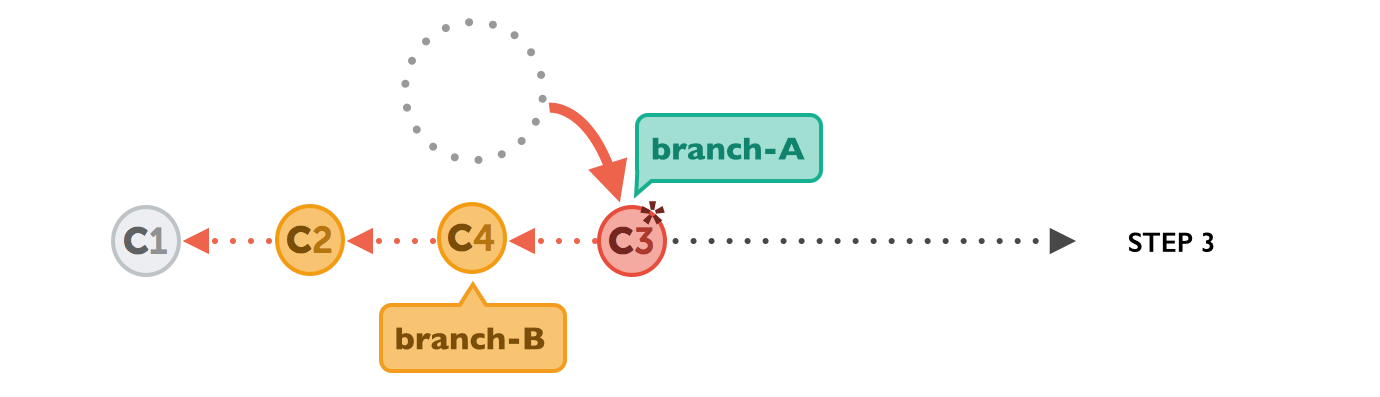
In the final step, the new commits on branch-A are now reapplied - but on a new position, on top of the integrated commits from branch-B (they are re-based).
The result looks like development had happened in a straight line. Instead of a merge commit that contains all the combined changes, the original commit structure was preserved.
The Pitfalls of Rebase
Of course, using rebase isn't just sunshine and roses. You can easily shoot yourself in the foot if you don't mind an important fact: rebase rewrites history.
As you might have noticed in the last diagram above, commit "C3*" has an asterisk symbol added. This is because, although it has the same contents as "C3", it's effectively a different commit. The reason for this is that it now has a new parent commit (C4, which it was rebased onto, compared to C1, when it was originally created).
A commit has only a handful of important properties like the author, date, changeset - and who its parent commit is. Changing any of this information effectively creates a completely new commit, with a new hash ID.
Rewriting history in such a way is unproblematic as long as it only affects commits that haven't been published, yet. If instead you're rewriting commits that have already been pushed to a public server, danger is at hand: another developer has probably already based work on the original C3 commit, making it indispensable for other newer commits. Now you introduce the contents of C3 another time (with C3*), and additionally try to remove the original C3 from the timeline with your rebase. This smells like trouble...
Therefore, you should use rebase only for cleaning up your local work - but never to rebase commits that have already been published.
Get our popular Git Cheat Sheet for free!
You'll find the most important commands on the front and helpful best practice tips on the back. Over 100,000 developers have downloaded it to make Git a little bit easier.

About Us
As the makers of Tower, the best Git client for Mac and Windows, we help over 100,000 users in companies like Apple, Google, Amazon, Twitter, and Ebay get the most out of Git.
Just like with Tower, our mission with this platform is to help people become better professionals.
That's why we provide our guides, videos, and cheat sheets (about version control with Git and lots of other topics) for free.